El descubrimiento científico usando minería de artículos científicos
https://francis.naukas.com/2019/07/04/el-descubrimiento-cientifico-usando-mineria-de-articulos-cientificos/?fbclid=IwAR1uweg_mVvXwJwKrsl5pC-B7qS3RKIvzhP87GV5Y1mXkhb9D13-LwwF3Yw

Los investigadores leemos muchos artículos científicos para encontrar
relaciones entre ellos que desvelen nuevas hipótesis que lleven a
nuevos descubrimientos. Todos los años se publican más de dos millones
de artículos científicos. ¿Cuánto conocimiento se oculta en sus
relaciones? Se publica en Nature el uso pionero de la minería de textos (text mining)
para el análisis automático de artículos científicos de ciencia de los
materiales. Se ha entrenado una red de neuronas artificiales para buscar
propiedades correlacionadas con la palabra «termoeléctrico»; se han
redescubierto 1820 materiales con esta propiedad analizando los
artículos publicados muchos años antes de su descubrimiento y 7663
materiales candidatos que podrían tener dicha propiedad.
La quimioinformática (chemoinformatics), también llamada informática de materiales (material informatics),
nació hace unos 20 años con el desarrollo de las bases de datos de
sustancias químicas y sus propiedades. La combinación de estas bases de
datos con el procesado del lenguaje natural, tanto supervisado como no
supervisado, permite desvelar nuevas hipótesis, por ejemplo, la
superconductividad potencial de un compuesto. En el nuevo artículo se ha
usado el software Word2vec, una herramienta de aprendizaje automático (machine learning)
no supervisado desarrollada en 2013 para desvelar relaciones semánticas
entre palabras (términos científicos de un diccionario). Se ha aplicado
Word2vec a los resúmenes (abstracts) de 1.5 millones
de artículos, preseleccionados entre 3.3 millones, publicados entre
1922 y 2018 en más de 1000 revistas. El algoritmo agrega los casi 500
000 términos en diferentes clases (clustering) en un espacio de 200 dimensiones y desvela relaciones semánticas entre ellos.
Sin lugar a dudas la inteligencia artificial va a revolucionar la
ciencia durante el siglo XXI. El artículo es Vahe Tshitoyan, John
Dagdelen, …, Anubhav Jain, «Unsupervised word embeddings capture latent
knowledge from materials science literature,» Nature 571: 95-98 (03 Jul
2019), doi: 10.1038/s41586-019-1335-8; más información en Olexandr Isayev, «Text mining facilitates materials discovery,» Nature 571: 42-43 (03 Jul 2019), doi: 10.1038/d41586-019-01978-x.

Esta figura ilustra el algoritmo Word2vec para dos términos, ‘LiCoO2’ y ‘LiMn2O4’,
entre los 500 000 del diccionario. Se representan con un vector con un
solo uno (1) en cierta posición (5 y 8 en la figura) y el resto de
componentes nulas (0). En un resumen (abstract) aparecen
múltiples términos del diccionario. Se entrena la red, que tiene una
capa oculta de unas 200 neuronas y una capa de salida con 500 000
neuronas, para reconocer (y relacionar) dichos términos. La capacidad de
generalización de la red de neuronas permite desvelar nuevas relaciones
entre los términos usando un análisis de componentes principales. En la
figura de la derecha se presentan las relaciones entre los términos Zr,
Cr y Ni con las propiedades ‘óxido de’ (Zr − ZrO2 ≈ Cr − Cr2O3 ≈ Ni − NiO) y ‘estructura (cristalina) de’ (Zr − HCP ≈ Cr − BCC ≈ Ni − FCC).
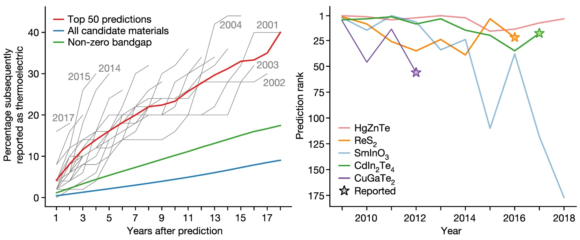
La figura izquierda presenta un resumen gráfico de las predicciones
para la palabra ‘termoeléctrico’. Las líneas grises están marcadas con
el año de la predicción, así la marcada con el año 2002 significa que se
usan artículos publicados entre 1922 y 2001; la línea roja es el
promedio de las líneas grises. En la figura de la derecha se presentan
las cinco predicciones con mayor certeza para el año 2009 (con artículos
entre 1922 y 2008) indicando el año en que se confirmó con una
estrella. Por ejemplo, CuGaTe2 se descubrió en 2012 y se podría haber predicho en 2009; más espectaculares son los casos de ReS2, termoeléctrico desde 2016, y CdIn2Te4, desde 2017. Las otras dos predicciones, HgZnTe y SmInO3, son materiales cuya termoelectricidad aún no ha sido confirmada (quizás se logre en un futuro no muy lejano).
Se han estudiado otros términos, como ‘fotovoltaico’, ‘aislante
topológico’ y ‘ferroeléctrico’ con resultados similares. Sin lugar a
dudas lo más interesante de este trabajo es el potencial futuro que
ofrece. Hay otros algoritmos similares a Word2vec (como GloVe), además
el diseño de la red de neuronas artificiales ofrece muchas posibilidades
de mejora, con lo que no tardarán en publicarse muchos otros trabajos
que usen la minería de textos para predecir nuevas hipótesis. Nos
encontramos al principio de una revolución en la manera de hacer
ciencia.
No hay comentarios:
Publicar un comentario